Au cours de la semaine dernière, j’ai observé de nombreux arguments contre l’approfondissement des 2 596 pages.
Mais la seule question que nous devrions nous poser est : « Comment puis-je tester et apprendre autant que possible à partir de ces documents ? »
Le référencement est une science appliquée où la théorie n’est pas l’objectif final mais la base d’expérimentations.
 Crédit image : Lyna™
Crédit image : Lyna™ Améliorez vos compétences grâce aux informations hebdomadaires d'experts de Growth Memo. Abonnez-vous gratuitement !
14 000 idées de tests
On ne pouvait pas rêver d'un meilleur terrain fertile pour les idées de tests. Mais nous ne pouvons pas tester tous les facteurs de la même manière. Ils ont différents types (nombre/entier : plage, booléen : oui/non, chaîne : mot/liste) et des temps de réaction (c'est-à-dire la vitesse à laquelle ils conduisent à un changement de rang organique).
En conséquence, nous pouvons tester A/B les facteurs rapides et actifs alors que nous devons tester avant/après les facteurs lents et passifs.
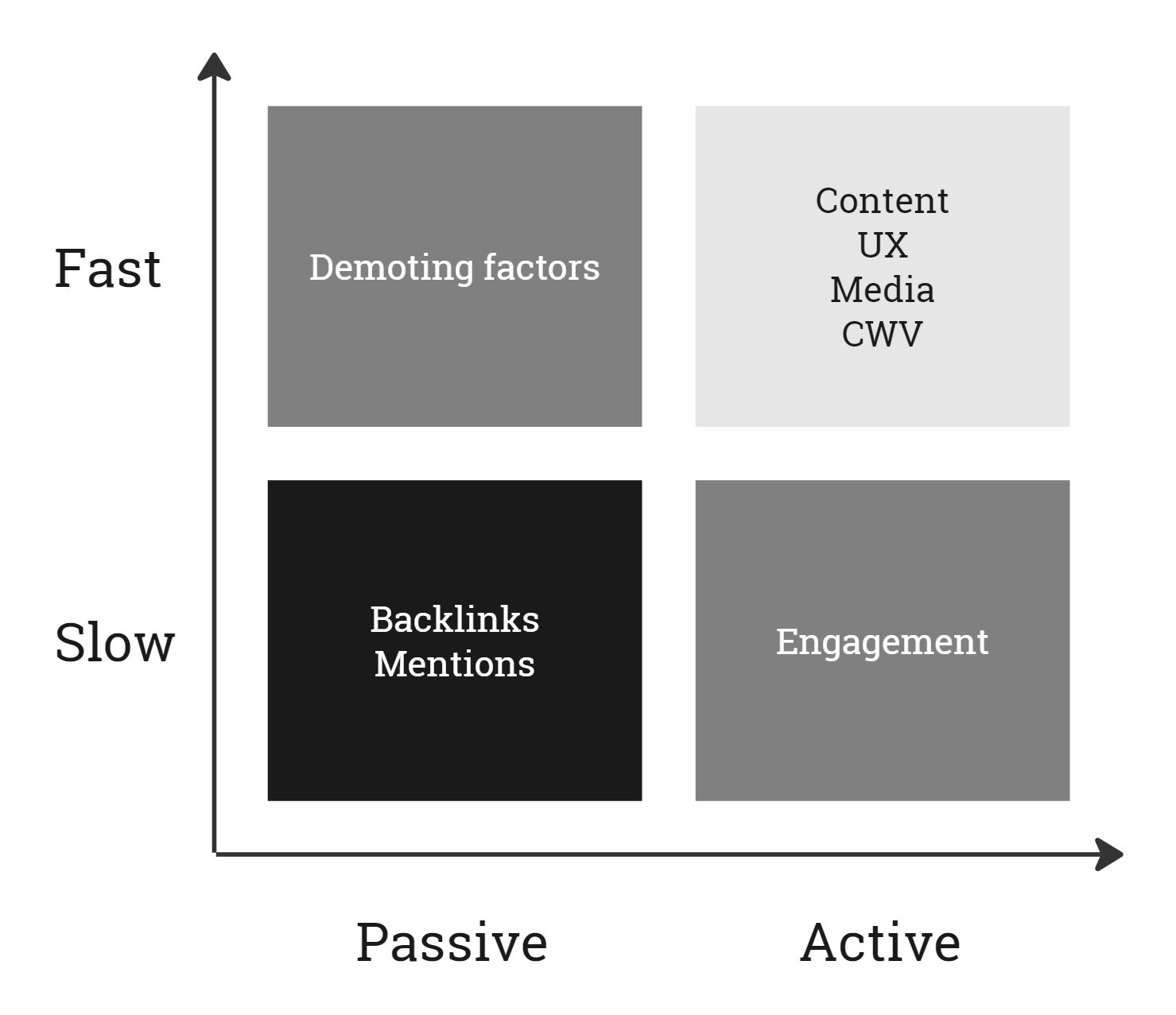 Priorisez les tests par vitesse. (Crédit image : Kevin Indig)
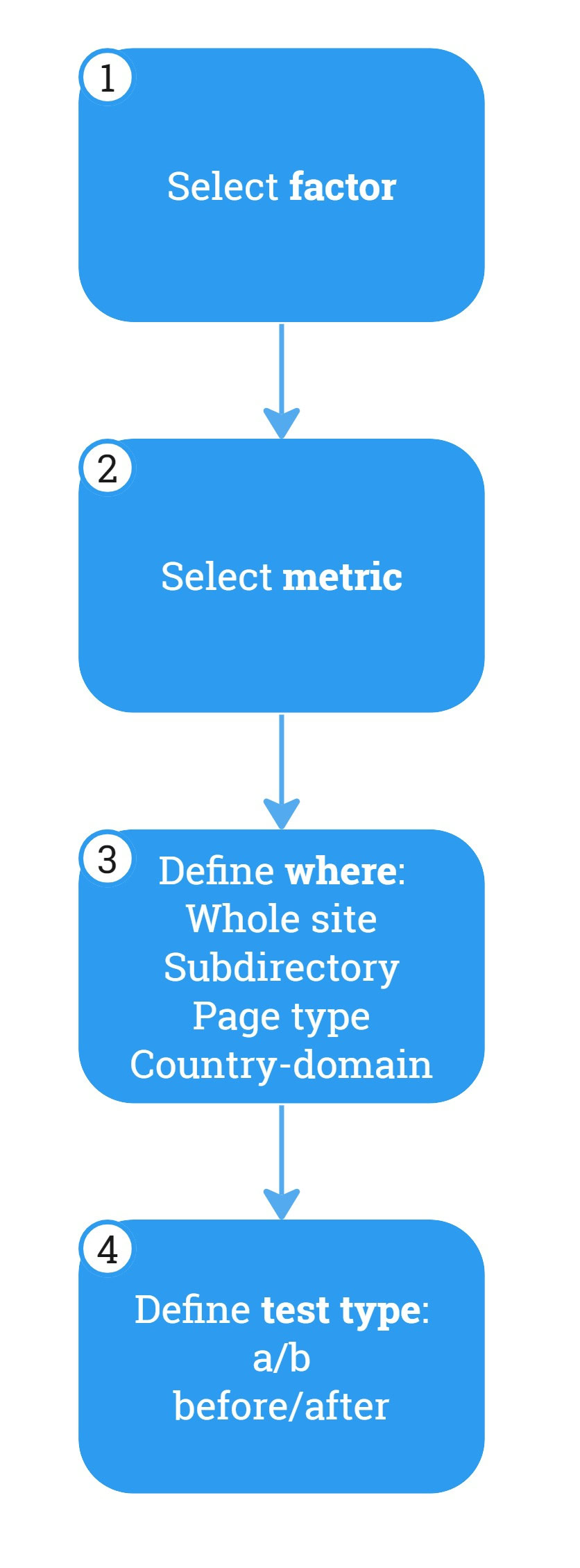
Priorisez les tests par vitesse. (Crédit image : Kevin Indig) Testez systématiquement les facteurs de classement en :
- Sélection d'un facteur de classement.
- Sélection de la métrique impactée (succès).
- Définissez où vous testez.
- Définir le type de test.
 Crédit image : Kevin Indig
Crédit image : Kevin Indig Facteurs de classement
La plupart des facteurs de classement dans la fuite sont des nombres entiers, ce qui signifie qu'ils fonctionnent sur un spectre, mais certains facteurs booléens sont faciles à tester :
- Compression d'image : Oui/Non ?
- Interstitiels intrusifs : Oui/Non ?
- Éléments essentiels du Web : oui/non ?
Facteurs que vous pouvez contrôler directement :
- UX (navigation, taille de police, interligne, qualité d'image).
- Contenu (titres frais et optimisés, non duplicatifs, riches en entités pertinentes, axés sur une seule intention d'utilisateur, efforts importants, créditant les sources originales, utilisant les formes canoniques d'un mot au lieu de l'argot, UGC de haute qualité, auteur expert).
- Engagement des utilisateurs (taux élevé d’achèvement des tâches).
Facteurs de classement rétrogradants (négatifs) :
- Liens provenant de pages et de domaines de mauvaise qualité.
- Texte d'ancrage agressif (sauf si vous avez un profil de lien extrêmement fort).
- Mauvaise navigation.
- Mauvais signaux des utilisateurs.
Facteurs sur lesquels vous ne pouvez influencer que passivement :
- Correspondance du titre et pertinence entre la source et le document lié.
- Clics sur les liens.
- Liens provenant de pages nouvelles et fiables.
- Autorité de domaine.
- Mentions de marque.
- PageRank de la page d'accueil.
Commencez par une évaluation de vos performances dans le domaine dans lequel vous souhaitez tester. Un cas d’utilisation simple serait Core Web Vitals.
Métrique
Choisissez la bonne métrique pour le bon facteur en fonction de la description contenue dans le document divulgué ou de votre compréhension de l'impact d'un facteur sur une métrique :
- Taux d'exploration.
- Indexation (Oui/Non).
- Classement (pour le mot-clé principal).
- Taux de clics (CTR).
- Fiançailles.
- Mots-clés pour lesquels une page est classée.
- Clics organiques.
- Impressions.
- Extraits riches.
Où tester
Trouvez le bon endroit pour tester :
- Si vous êtes sceptique, utilisez un domaine spécifique à un pays ou un site sur lequel vous pouvez tester à faible risque. Si vous disposez d'un site dans plusieurs langues, vous pouvez déployer des modifications en fonction des fuites dans un pays et comparer les performances relatives par rapport à votre pays principal.
- Vous pouvez limiter les tests à un type ou à un sous-répertoire d’une page pour isoler au mieux l’impact.
- Limitez les tests aux pages traitant d'un type spécifique de mot-clé (par exemple, « Meilleur X ») ou d'intention de l'utilisateur (par exemple, « Lire les avis »).
Certains facteurs de classement sont des signaux à l'échelle du site, comme l'autorité du site, et d'autres sont spécifiques à une page, comme les taux de clics.
Considérations
Les facteurs de classement peuvent fonctionner les uns avec les autres ou les uns contre les autres puisqu’ils font partie d’une équation.
Les humains sont notoirement mauvais pour comprendre intuitivement les fonctions comportant de nombreuses variables, ce qui signifie que nous sous-estimons probablement l'importance de l'obtention d'un score de rang élevé, mais également l'impact significatif de quelques variables sur le résultat.
La grande complexité de la relation entre les facteurs de classement ne devrait pas nous empêcher d’expérimenter.
Les agrégateurs peuvent tester plus facilement que les intégrateurs car ils ont des pages plus comparables qui conduisent à des résultats plus significatifs. Les intégrateurs, qui doivent créer eux-mêmes le contenu, présentent des différences entre chaque page qui diluent les résultats des tests.
Mon test préféré : l'une des meilleures choses que vous puissiez faire pour votre compréhension du référencement est d'évaluer les facteurs de classement selon votre propre perception, puis de remettre en question et de tester systématiquement vos hypothèses. Créez une feuille de calcul avec chaque facteur de classement, attribuez-lui un nombre compris entre zéro et un en fonction de votre idée de son importance et multipliez tous les facteurs.
Systèmes de surveillance
Les tests ne nous donnent qu'une première réponse sur l'importance des facteurs de classement. La surveillance nous permet de mesurer les relations au fil du temps et de tirer des conclusions plus solides.
L'idée est de suivre les mesures qui reflètent les facteurs de classement, comme le CTR pourrait refléter l'optimisation du titre, et de les tracer au fil du temps pour voir si l'optimisation porte ses fruits. L'idée n'est pas différente de la surveillance régulière (ou de ce qui devrait être régulière), à l'exception des nouvelles mesures.
Vous pouvez créer des systèmes de surveillance dans :
- Looker.
- Amplitude.
- Panneau mixte.
- Tableau.
- Domo.
- Geckoboard.
- Bonnes données.
- Power BI.
L'outil n'est pas aussi important que les bonnes mesures et le bon chemin d'URL.
Exemples de métriques
Mesurez les métriques par type de page ou par ensemble d'URL au fil du temps pour mesurer l'impact des optimisations.
Remarque : j'utilise des seuils basés sur mon expérience personnelle que vous devriez contester.
Engagement des utilisateurs :
- Nombre moyen de clics sur la navigation.
- Profondeur de défilement moyenne.
- CTR (SERP vers site).
Qualité du backlink :
- % de liens avec une adéquation élevée au sujet/au titre entre la source et la cible.
- % de liens vers des pages datant de moins d'un an.
- % de liens provenant de pages classées pour au moins un mot-clé dans le top 10.
Qualité des pages :
- Temps de séjour moyen (comparé entre pages du même type).
- % d'utilisateurs qui passent au moins 30 secondes sur le site.
- % de pages classées dans le top 3 pour leur mot-clé cible.
Qualité du site :
- % de pages qui génèrent du trafic organique.
- % d'URL sans clic au cours des 90 derniers jours.
- Rapport entre pages indexées et non indexées.
Il est ironique que la fuite se soit produite peu de temps après que Google ait commencé à afficher l'IA pour les résultats ( AI Overviews ), car nous pouvons utiliser l'IA pour trouver des lacunes en matière de référencement en fonction de la fuite.
Un exemple est la correspondance de titre entre la source et la cible pour les backlinks. Avec les outils de référencement courants, nous pouvons extraire les titres, le texte d’ancrage et le contenu environnant du lien pour les pages de référence et cibles.
Nous pouvons ensuite évaluer la proximité thématique ou le chevauchement des jetons avec des outils d'IA courants, des intégrations Google Sheets/Excel ou des LLM locaux et des invites de base telles que « Évaluez la proximité thématique du titre (colonne B) par rapport à l'ancre (colonne C) sur un sujet. échelle de 1 à 10, 10 étant exactement le même et 1 n’ayant aucune relation.
 Utiliser l'IA pour évaluer la correspondance des titres entre les sources et les cibles des liens. (Crédit image : Kevin Indig)
Utiliser l'IA pour évaluer la correspondance des titres entre les sources et les cibles des liens. (Crédit image : Kevin Indig) Une fuite qui leur est propre
La fuite du facteur de classement de Google n'est pas la première fois que les travaux internes d'un algorithme de grande plate-forme deviennent accessibles au public :
1. En janvier 2023, une fuite Yandex a révélé de nombreux facteurs de classement que nous avons également trouvés dans la dernière fuite Google. La réaction décevante m’a autant surpris à l’époque qu’aujourd’hui.
2. En mars 2023, Twitter a publié la plupart des parties de son algorithme. Semblable à la fuite de Google, elle manque de « contexte » entre les facteurs, mais elle était néanmoins perspicace. 1
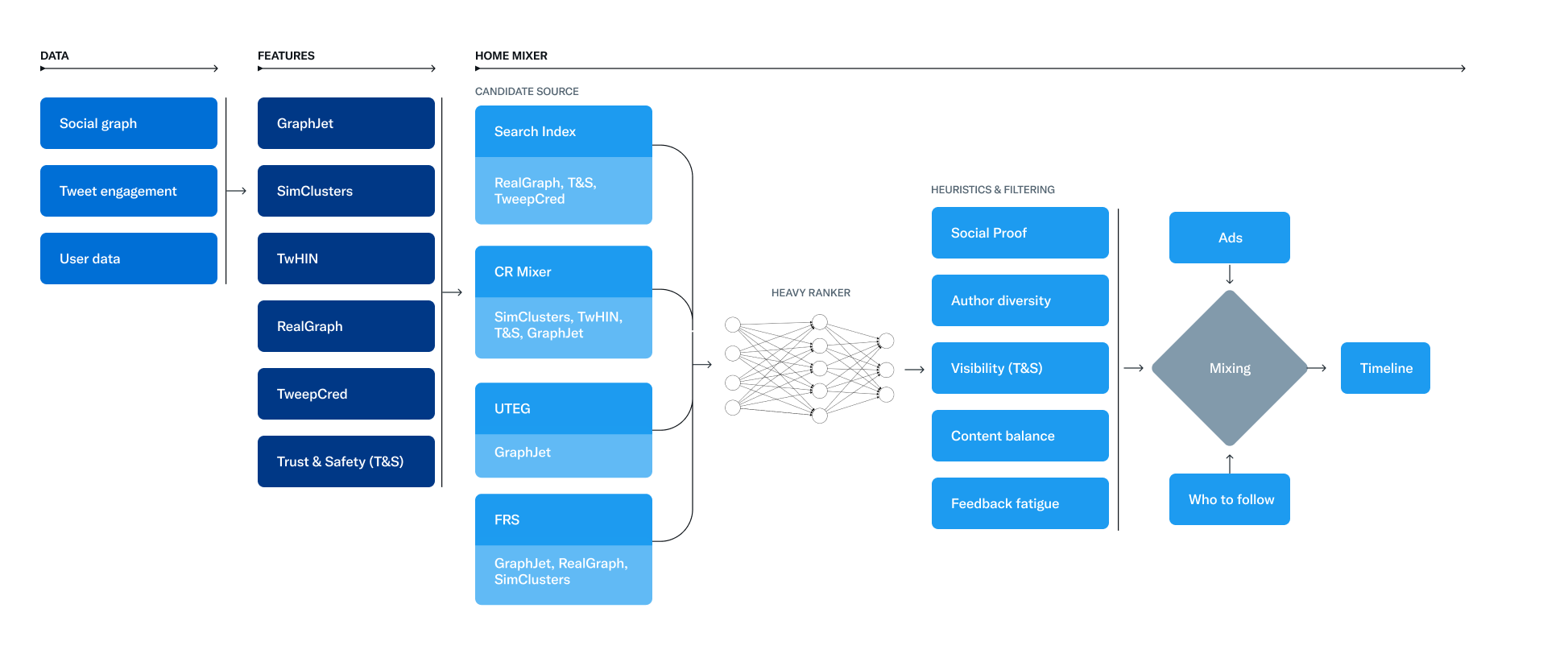 L'algorithme de Twitter dans un graphique système. (Crédit image : Kevin Indig)
L'algorithme de Twitter dans un graphique système. (Crédit image : Kevin Indig) 3. Également en mars 2023, Adam Mosseri, directeur d'Instagram, a publié un article de suivi approfondi sur la manière dont la plateforme classe le contenu dans différentes parties de son produit. 2
Malgré les fuites, il n’existe aucun cas connu d’utilisateur ou de marque piratant la plateforme de manière propre et éthique.
Plus une plateforme récompense l’engagement dans son algorithme, plus il est difficile de jouer. Et pourtant, la fuite de l’algorithme de Google est assez intéressante car il s’agit d’une plateforme basée sur l’intention où les utilisateurs indiquent leur intérêt par le biais de recherches plutôt que par leur comportement.
En conséquence, connaître les ingrédients du gâteau est un grand pas en avant, même sans savoir quelle quantité utiliser de chacun.
Je ne comprends pas pourquoi Google a toujours été si secret sur les facteurs de classement. Je ne dis pas qu'il aurait dû les publier quant à l'ampleur de la fuite. Cela aurait pu encourager un meilleur Web avec des sites rapides, faciles à naviguer, esthétiques et informatifs.
Au lieu de cela, cela a laissé les gens trop deviner, ce qui a conduit à beaucoup de contenu de mauvaise qualité, ce qui a conduit à des mises à jour d'algorithmes qui ont coûté beaucoup d'argent à de nombreuses entreprises.
1 Diagramme système de Github.com
2 Le classement Instagram expliqué
Image en vedette : Paulo Bobita/Search Engine Journal



