Si vous êtes un praticien du référencement ou un spécialiste du marketing numérique et que vous lisez cet article, vous avez peut-être expérimenté l'IA et les chatbots dans votre travail quotidien.
Mais la question est : comment tirer le meilleur parti de l’IA autrement qu’en utilisant une interface utilisateur de chatbot ?
Pour cela, vous avez besoin d’une compréhension approfondie du fonctionnement des grands modèles de langage (LLM) et d’apprendre le niveau de base du codage. Et oui, le codage est aujourd’hui absolument nécessaire pour réussir en tant que professionnel du référencement.
Il s'agit du premier d'une série d'articles visant à améliorer vos compétences afin que vous puissiez commencer à utiliser les LLM pour faire évoluer vos tâches de référencement. Nous pensons qu'à l'avenir, cette compétence sera nécessaire pour réussir.
Nous devons partir de l’essentiel. Il comprendra des informations essentielles, donc plus tard dans cette série, vous pourrez utiliser les LLM pour adapter vos efforts de référencement ou de marketing aux tâches les plus fastidieuses.
Contrairement à d’autres articles similaires que vous avez lus, nous commencerons ici par la fin. La vidéo ci-dessous illustre ce que vous pourrez faire après avoir lu tous les articles de la série sur la façon d'utiliser les LLM pour le référencement.
Notre équipe utilise cet outil pour accélérer les liens internes tout en maintenant une surveillance humaine.
Avez-vous apprécié? C’est ce que vous pourrez très prochainement construire vous-même.
Commençons maintenant par les bases et vous dotons des connaissances de base requises en LLM.
Que sont les vecteurs ?
En mathématiques, les vecteurs sont des objets décrits par une liste ordonnée de nombres (composants) correspondant aux coordonnées dans l'espace vectoriel.
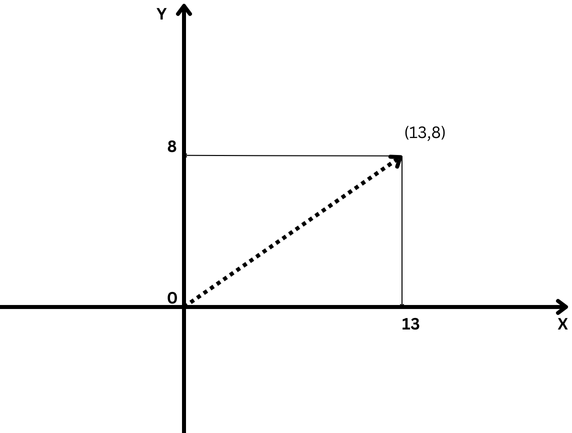
Un exemple simple de vecteur est un vecteur dans un espace bidimensionnel, représenté par (x,y)coordonnées comme illustré ci-dessous.
Exemple de vecteur bidimensionnel avec les coordonnées x=13 et y=8 notées comme (13,8)
Dans ce cas, la coordonnée x=13 représente la longueur de la projection du vecteur sur l'axe X, et y=8 représente la longueur de la projection du vecteur sur l'axe Y.
Les vecteurs définis avec des coordonnées ont une longueur, appelée grandeur d'un vecteur ou norme. Pour notre cas simplifié bidimensionnel, il est calculé par la formule :
Cependant, les mathématiciens sont allés plus loin et ont défini des vecteurs avec un nombre arbitraire de coordonnées abstraites (X1, X2, X3… Xn), appelés vecteurs « à N dimensions » .
Dans le cas d’un vecteur dans un espace tridimensionnel, cela représenterait trois nombres (x, y, z), que nous pouvons toujours interpréter et comprendre, mais tout ce qui dépasse cela sort de notre imagination et tout devient un concept abstrait.
Et c’est ici que les intégrations LLM entrent en jeu.
Qu’est-ce que l’intégration de texte ?
Les intégrations de texte sont un sous-ensemble des intégrations LLM, qui sont des vecteurs abstraits de haute dimension représentant du texte qui capturent les contextes sémantiques et les relations entre les mots.
Dans le jargon LLM, les « mots » sont appelés jetons de données, chaque mot étant un jeton. De manière plus abstraite, les intégrations sont des représentations numériques de ces jetons, codant les relations entre tous les jetons de données (unités de données), où un jeton de données peut être une image, un enregistrement sonore, un texte ou une image vidéo.
Afin de calculer la proximité sémantique des mots, nous devons les convertir en nombres. Tout comme vous soustrayez des nombres (par exemple, 10-6 = 4) et que vous pouvez dire que la distance entre 10 et 6 est de 4 points, il est possible de soustraire des vecteurs et de calculer la distance entre les deux vecteurs.
Ainsi, comprendre les distances vectorielles est important afin de comprendre le fonctionnement des LLM.
Il existe différentes manières de mesurer la proximité des vecteurs :
Distance euclidienne.
Similitude ou distance cosinus.
Ressemblance Jaccard.
Distance de Manhattan.
Chacun a ses propres cas d’utilisation, mais nous ne discuterons que des distances cosinusoïdales et euclidiennes couramment utilisées.
Quelle est la similarité cosinus ?
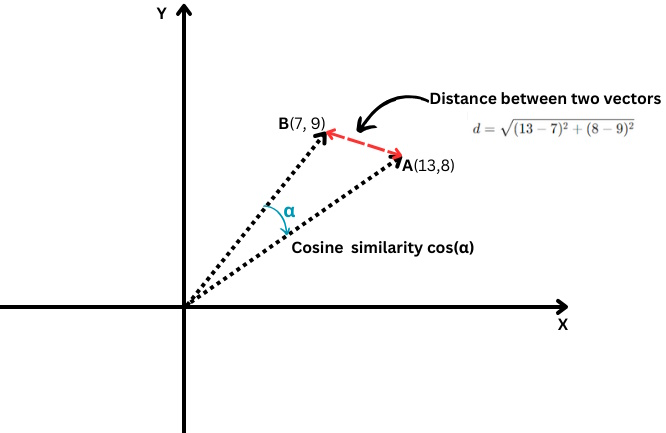
Il mesure le cosinus de l'angle entre deux vecteurs, c'est-à-dire le degré d'alignement de ces deux vecteurs l'un par rapport à l'autre.
Distance euclidienne vs similarité cosinus
Il est défini comme suit :
Où le produit scalaire de deux vecteurs est divisé par le produit de leurs grandeurs, c'est-à-dire leurs longueurs.
Ses valeurs vont de -1, ce qui signifie complètement opposé, à 1, ce qui signifie identique. Une valeur de « 0 » signifie que les vecteurs sont perpendiculaires.
En termes d'incorporation de texte, il est peu probable qu'il soit possible d'atteindre la valeur exacte de similarité cosinusoïdale de -1, mais voici des exemples de textes avec 0 ou 1 similarité cosinusoïdale.
Similitude cosinus = 1 (identique)
«Top 10 des joyaux cachés pour les voyageurs solitaires à San Francisco»
«Top 10 des joyaux cachés pour les voyageurs solitaires à San Francisco»
Ces textes sont identiques, donc leurs intégrations seraient les mêmes, ce qui donnerait une similarité cosinus de 1.
Similarité cosinus = 0 (perpendiculaire, ce qui signifie sans rapport)
"Mécanique quantique"
"J'adore les jours de pluie"
Ces textes sont totalement indépendants, ce qui entraîne une similarité cosinusoïdale de 0 entre leurs intégrations BERT .
(Remarque : nous apprendrons en détail dans les prochains chapitres à pratiquer les intégrations à l'aide de Python et Jupyter ).
Modèle text-'embedding-preview-0409' de Vertex Ai Le modèle « text-embedding-3-small » d'OpenAi
Nous ignorons le cas avec similarité cosinus = -1 car il est très peu probable que cela se produise.
Si vous essayez d'obtenir une similarité cosinus pour un texte ayant des significations opposées comme « amour » contre « haine » ou « le projet réussi » contre « le projet en échec », vous obtiendrez une similarité cosinus de 0,5 à 0,6 avec le « texte- » de Google Vertex AI. Modèle d'intégration-preview-0409' .
En effet, les mots « amour » et « haine » apparaissent souvent dans des contextes similaires liés aux émotions, et « réussite » et « échec » sont tous deux liés aux résultats du projet. Les contextes dans lesquels ils sont utilisés peuvent se chevaucher de manière significative dans les données de formation.
La similarité cosinus peut être utilisée pour les tâches de référencement suivantes :
Classification.
Regroupement de mots clés.
Implémentation de redirections.
Lien interne.
Détection de contenu en double.
Recommandation de contenu.
Analyse de la concurrence.
La similarité cosinus se concentre sur la direction des vecteurs (l'angle entre eux) plutôt que sur leur ampleur (longueur). En conséquence, il peut capturer la similarité sémantique et déterminer le degré d’alignement de deux éléments de contenu, même si l’un est beaucoup plus long ou utilise plus de mots que l’autre.
Plonger en profondeur et explorer chacun de ces éléments sera l’objectif des prochains articles que nous publierons.
Quelle est la distance euclidienne ?
Dans le cas où vous disposez de deux vecteurs A(X1,Y1) et B(X2,Y2), la distance euclidienne est calculée par la formule suivante :
C’est comme utiliser une règle pour mesurer la distance entre deux points (la ligne rouge dans le tableau ci-dessus).
La distance euclidienne peut être utilisée pour les tâches de référencement suivantes :
Évaluer la densité des mots clés dans le contenu.
Trouver du contenu en double avec une structure similaire.
Analyse de la distribution du texte d'ancrage.
Regroupement de mots clés.
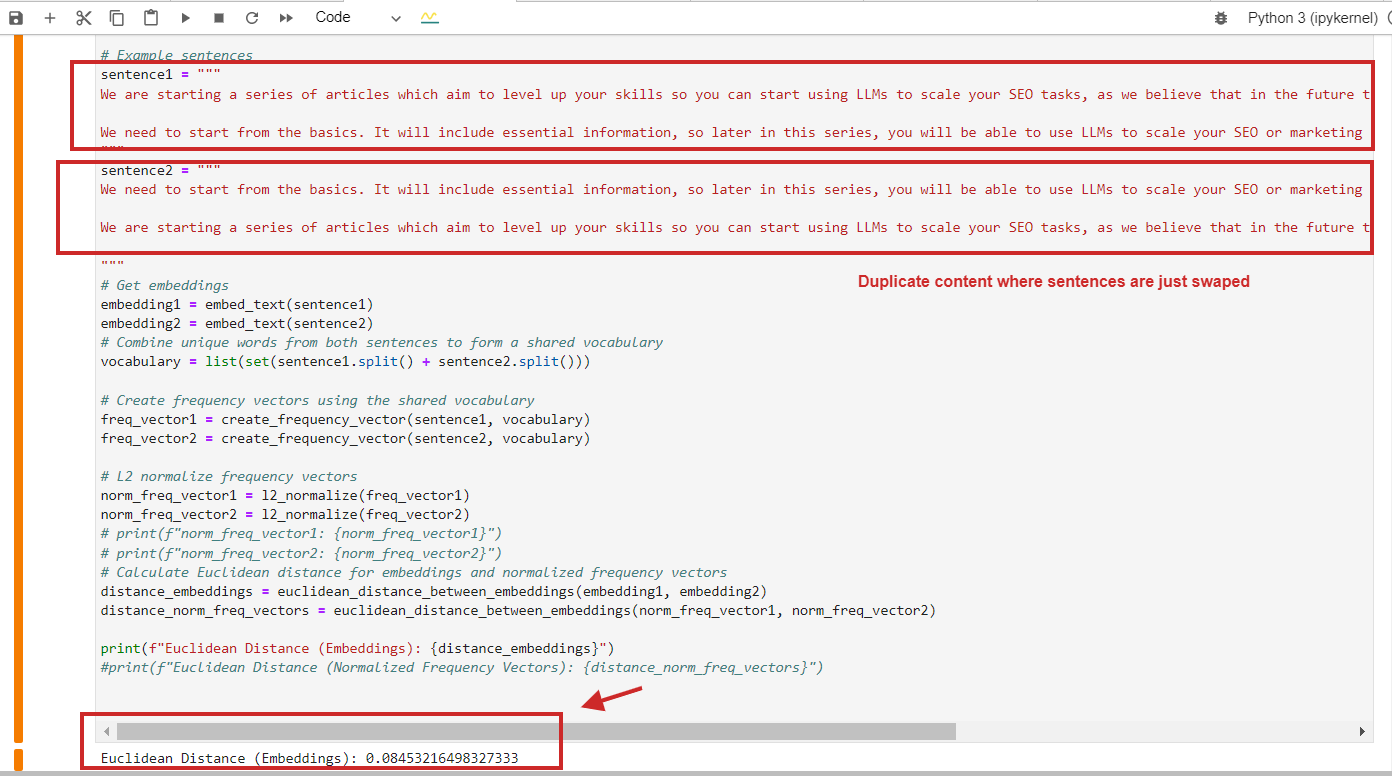
Voici un exemple de calcul de distance euclidienne avec une valeur de 0,08, presque proche de 0, pour un contenu en double où les paragraphes sont simplement échangés – ce qui signifie que la distance est de 0, c'est-à-dire que le contenu que nous comparons est le même.
Exemple de calcul de distance euclidienne de contenu dupliqué
Bien sûr, vous pouvez utiliser la similarité cosinus, et il détectera le contenu en double avec une similarité cosinus 0,9 sur 1 (presque identique).
Voici un point clé à retenir : vous ne devez pas vous fier uniquement à la similarité cosinusoïdale, mais également utiliser d'autres méthodes, car le document de recherche de Netflix suggère que l'utilisation de la similarité cosinusoïdale peut conduire à des « similarités » dénuées de sens.
Nous montrons que la similarité cosinusoïdale des plongements appris peut en fait donner des résultats arbitraires. Nous constatons que la raison sous-jacente n’est pas la similarité cosinus elle-même, mais le fait que les plongements appris ont un degré de liberté qui peut rendre des similarités cosinus arbitraires.
En tant que professionnel du référencement, vous n'avez pas besoin d'être en mesure de comprendre pleinement ce document, mais n'oubliez pas que les recherches montrent que d'autres méthodes à distance, telles que la méthode euclidienne, doivent être envisagées en fonction des besoins du projet et des résultats obtenus pour réduire les faux. résultats positifs.
Qu'est-ce que la normalisation L2 ?
La normalisation L2 est une transformation mathématique appliquée aux vecteurs pour en faire des vecteurs unitaires d'une longueur de 1.
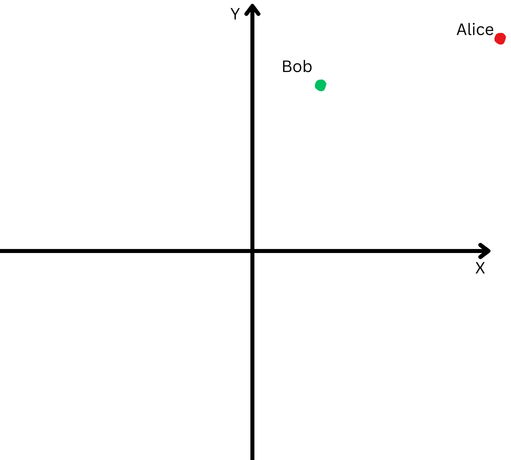
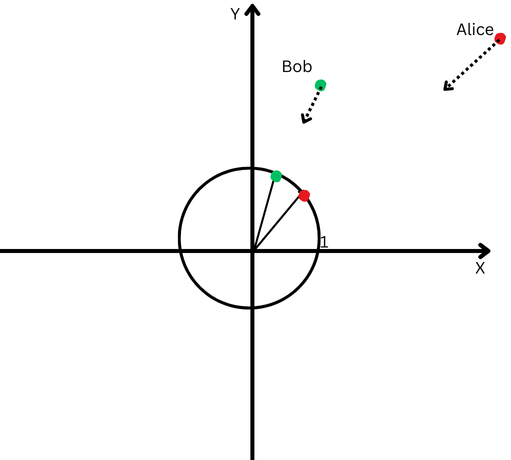
Pour expliquer en termes simples, disons que Bob et Alice ont parcouru une longue distance. Maintenant, nous voulons comparer leurs directions. Ont-ils suivi des chemins similaires ou sont-ils allés dans des directions complètement différentes ?
« Alice » est représentée par un point rouge dans le quadrant supérieur droit et « Bob » est représenté par un point vert.
Cependant, comme ils sont loin de leur origine, nous aurons du mal à mesurer l’angle entre leurs trajectoires car ils sont allés trop loin.
En revanche, on ne peut pas prétendre que s’ils sont éloignés les uns des autres, cela signifie que leurs chemins sont différents.
La normalisation L2 revient à ramener Alice et Bob à la même distance plus proche du point de départ, disons à un pied de l'origine, pour faciliter la mesure de l'angle entre leurs trajectoires.
Maintenant, nous voyons que même s’ils sont éloignés les uns des autres, leurs directions de trajectoire sont assez proches.
Un plan cartésien avec un cercle centré à l'origine.
Cela signifie que nous avons supprimé l'effet de leurs différentes longueurs de trajet (c'est-à-dire la magnitude des vecteurs) et pouvons nous concentrer uniquement sur la direction de leurs mouvements.
Dans le contexte des incorporations de textes, cette normalisation nous aide à nous concentrer sur la similarité sémantique entre les textes (la direction des vecteurs).
La plupart des modèles d'intégration, tels que les modèles « text-embedding-3-large » d'OpeanAI ou « text-embedding-preview-0409 » de Google Vertex AI, renvoient des intégrations pré-normalisées, ce qui signifie que vous n'avez pas besoin de normaliser.
Mais, par exemple, les intégrations du modèle BERT « bert-base-uncased » ne sont pas pré-normalisées.
Conclusion
C'était le chapitre d'introduction de notre série d'articles pour vous familiariser avec le jargon des LLM, qui, je l'espère, a rendu l'information accessible sans avoir besoin d'un doctorat en mathématiques.
Si vous avez encore du mal à les mémoriser, ne vous inquiétez pas. Au fur et à mesure que nous aborderons les sections suivantes, nous ferons référence aux définitions définies ici et vous pourrez les comprendre grâce à la pratique.
Les prochains chapitres seront encore plus intéressants :
Introduction aux intégrations de texte d'OpenAI avec des exemples.
Introduction aux intégrations de texte Vertex AI de Google avec des exemples.
Introduction aux bases de données vectorielles.
Comment utiliser les intégrations LLM pour les liens internes.
Comment utiliser les intégrations LLM pour implémenter des redirections à grande échelle.
Rassembler le tout : plugin WordPress basé sur LLM pour les liens internes.
L’objectif est d’améliorer vos compétences et de vous préparer à relever les défis du référencement.
Beaucoup d'entre vous diront peut-être qu'il existe des outils que vous pouvez acheter qui effectuent ce genre de choses automatiquement, mais ces outils ne seront pas en mesure d'effectuer de nombreuses tâches spécifiques en fonction des besoins de votre projet, ce qui nécessite une approche personnalisée.
Utiliser des outils SEO, c’est toujours bien, mais avoir des compétences, c’est encore mieux !
Davantage de ressources:
SEO technique : la liste de contrôle de la semaine de travail de 20 minutes
20 outils de référencement technique essentiels pour les agences
Le cahier d’exercices complet d’audit technique SEO