Le fichier robots.txt du blog personnel de John Mueller de Google est devenu un centre d'intérêt lorsque quelqu'un sur Reddit a affirmé que le blog de Mueller avait été touché par le système de contenu utile et ensuite désindexé. La vérité s’est avérée moins dramatique que ça mais c’était quand même un peu bizarre.
Publication du sous-reddit SEO
La saga du fichier robots.txt de John Mueller a commencé lorsqu'un utilisateur de Reddit a publié que le site Web de John Mueller avait été désindexé, indiquant qu'il enfreignait l'algorithme de Google. Mais aussi ironique que cela puisse être, cela n'a jamais été le cas, car il a suffi de quelques secondes pour charger le fichier robots.txt du site Web et voir que quelque chose d'étrange se passait.
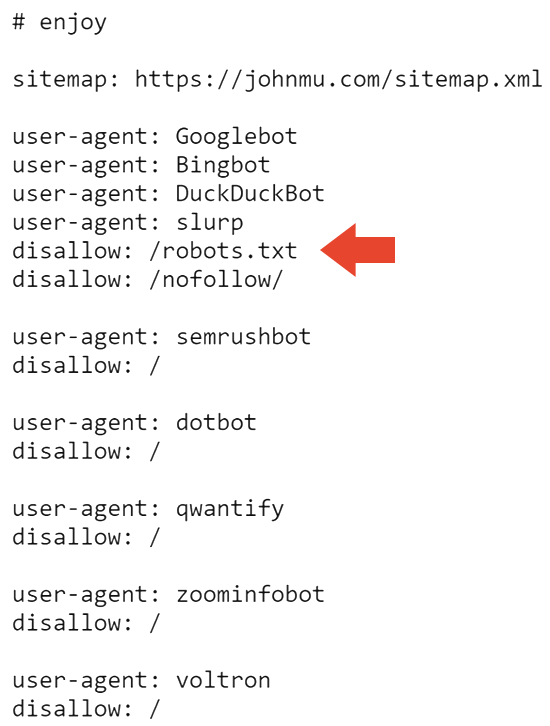
Voici la partie supérieure du fichier robots.txt de Mueller qui présente un œuf de Pâques commenté pour ceux qui y jettent un coup d'œil.
Le premier élément que l'on ne voit pas tous les jours est une interdiction sur le fichier robots.txt. Qui utilise son fichier robots.txt pour dire à Google de ne pas explorer son fichier robots.txt ?
Maintenant nous le savons.
La partie suivante du fichier robots.txt empêche tous les moteurs de recherche d'explorer le site Web et le fichier robots.txt.
Cela explique donc probablement pourquoi le site est désindexé dans Google. Mais cela n'explique pas pourquoi il est toujours indexé par Bing.
J'ai demandé autour de moi et Adam Humphreys, développeur Web et SEO ( profil LinkedIn ), a suggéré qu'il se pourrait que Bingbot n'ait pas visité le site de Mueller car il s'agit d'un site Web en grande partie inactif.
Dans ces exemples, les dossiers et ce fichier dans ce dossier ne seraient pas trouvés.
Il dit d'interdire le fichier robots que Bing ignore mais que Google écoute.
Bing ignorerait les robots mal implémentés car beaucoup ne savent pas comment le faire. "
Adam a également suggéré que Bing avait peut-être complètement ignoré le fichier robots.txt.
Il me l'a expliqué ainsi :
« Oui ou il choisit d'ignorer une directive pour ne pas lire un fichier d'instructions.
Les instructions des robots mal mises en œuvre sur Bing sont probablement ignorées. C'est pour eux la réponse la plus logique. C'est un fichier d'itinéraires.
Le fichier robots.txt a été mis à jour pour la dernière fois entre juillet et novembre 2023, il se peut donc que Bingbot n'ait pas vu le dernier fichier robots.txt. Cela est logique car le système d'exploration Web IndexNow de Microsoft donne la priorité à une exploration efficace.
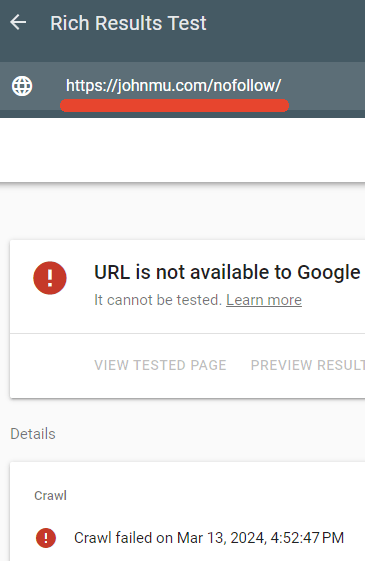
L'un des répertoires bloqués par le fichier robots.txt de Mueller est /nofollow/ (qui est un nom étrange pour un dossier).
Il n'y a pratiquement rien sur cette page, à l'exception de la navigation sur le site et du mot Redirector.
J'ai testé pour voir si le robots.txt bloquait effectivement cette page et c'était le cas.
Le testeur de résultats enrichis de Google n'a pas réussi à explorer la page Web /nofollow/.
L'explication de John Mueller
Mueller a semblé amusé qu'autant d'attention soit accordée à son fichier robots.txt et il a publié une explication sur LinkedIn de ce qui se passait.
Il a écrit:
« Mais qu'en est-il du dossier ? Et pourquoi votre site est-il désindexé ?
Quelqu'un a suggéré que cela pourrait être dû aux liens vers Google+. C'est possible. Et revenons au fichier robots.txt… tout va bien – je veux dire, c'est comme je le veux, et les robots d'exploration peuvent le gérer. Ou bien, ils devraient pouvoir le faire s’ils suivent la RFC9309.
Ensuite, il a déclaré que le nofollow sur le fichier robots.txt visait simplement à l'empêcher d'être indexé en tant que fichier HTML.
Il expliqua:
« »disallow: /robots.txt » – est-ce que cela fait tourner les robots en rond ? Est-ce que cela désindexe votre site ? Non.
Mon fichier robots.txt contient beaucoup de choses, et il est plus propre s'il n'est pas indexé avec son contenu. Cela empêche simplement l'exploration du fichier robots.txt à des fins d'indexation.
Je pourrais également utiliser l'en-tête HTTP x-robots-tag avec noindex, mais de cette façon, je l'ai également dans le fichier robots.txt.
Mueller a également dit ceci à propos de la taille du fichier :
« La taille provient des tests des différents outils de test robots.txt sur lesquels mon équipe et moi avons travaillé. La RFC indique qu'un robot d'exploration doit analyser au moins 500 kibioctets (bonus j'aime à la première personne qui explique de quel type de collation il s'agit). Il faut s'arrêter quelque part, on pourrait faire des pages infiniment longues (et je l'ai fait, et beaucoup de gens l'ont fait, certains même exprès). En pratique, ce qui se passe, c'est que le système qui vérifie le fichier robots.txt (l'analyseur) fera une coupure quelque part.
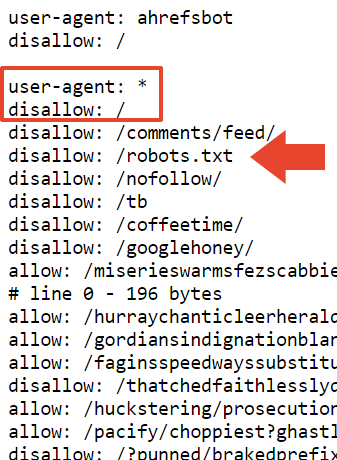
Il a également déclaré qu'il avait ajouté une interdiction en plus de cette section dans l'espoir qu'elle soit considérée comme une « interdiction générale », mais je ne suis pas sûr de quelle interdiction il parle. Son fichier robots.txt contient exactement 22 433 interdictions.
Il a écrit:
«J'ai ajouté un « interdiction : / » en haut de cette section, j'espère donc que cela sera considéré comme une interdiction générale. Il est possible que l'analyseur s'arrête à un endroit gênant, comme une ligne qui contient «allow: /cheeseisbest» et s'arrête juste au «/», ce qui mettrait l'analyseur dans une impasse (et, trivial ! la règle d'autorisation sera prioritaire si vous avez à la fois « autoriser : / » et « interdire : / »). Cela semble cependant très improbable.