Dans un récent article sur LinkedIn, Gary Illyes, analyste chez Google, met en évidence les aspects moins connus du fichier robots.txt alors qu'il fête son 30e anniversaire.
Le fichier robots.txt, un composant d'exploration et d'indexation Web, est un pilier des pratiques de référencement depuis sa création.
Voici une des raisons pour lesquelles il reste utile.
Gestion robuste des erreurs
Illyes a souligné la résistance du dossier aux erreurs.
"robots.txt est pratiquement sans erreur", a déclaré Illyes.
Dans son article, il a expliqué que les analyseurs robots.txt sont conçus pour ignorer la plupart des erreurs sans compromettre la fonctionnalité.
Cela signifie que le fichier continuera à fonctionner même si vous incluez accidentellement du contenu sans rapport ou des directives mal orthographiées.
Il a expliqué que les analyseurs reconnaissent et traitent généralement les directives clés telles que l'agent utilisateur, l'autorisation et l'interdiction, tout en ignorant le contenu non reconnu.
Fonctionnalité inattendue : commandes de ligne
Illyes a souligné la présence de lignes de commentaires dans les fichiers robots.txt, une fonctionnalité qu'il trouve déroutante compte tenu de la nature tolérante aux erreurs du fichier.
Il a invité la communauté SEO à spéculer sur les raisons de cette inclusion.
Réponses au message d'Illyes
La réponse de la communauté SEO au message d'Illyes fournit un contexte supplémentaire sur les implications pratiques de la tolérance aux erreurs de robots.txt et de l'utilisation de commentaires en ligne.
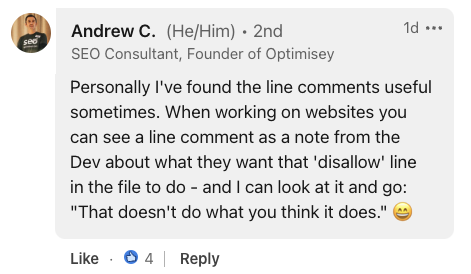
Andrew C., fondateur d'Optimisey, a souligné l'utilité des commentaires en ligne pour la communication interne, déclarant :
"Lorsque vous travaillez sur des sites Web, vous pouvez voir une ligne de commentaire comme une note du développeur sur ce qu'il veut que cette ligne 'interdire' dans le fichier fasse."
 Capture d'écran de LinkedIn, juillet 2024.
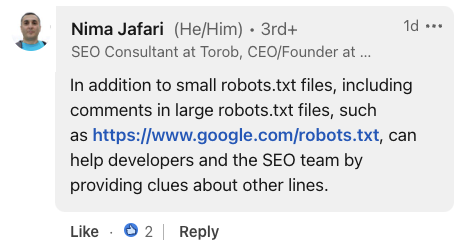
Capture d'écran de LinkedIn, juillet 2024. Nima Jafari, consultante SEO, a souligné la valeur des commentaires dans les mises en œuvre à grande échelle.
Il a noté que pour les fichiers robots.txt volumineux, les commentaires peuvent « aider les développeurs et l'équipe SEO en fournissant des indices sur d'autres lignes ».
 Capture d'écran de LinkedIn, juillet 2024.
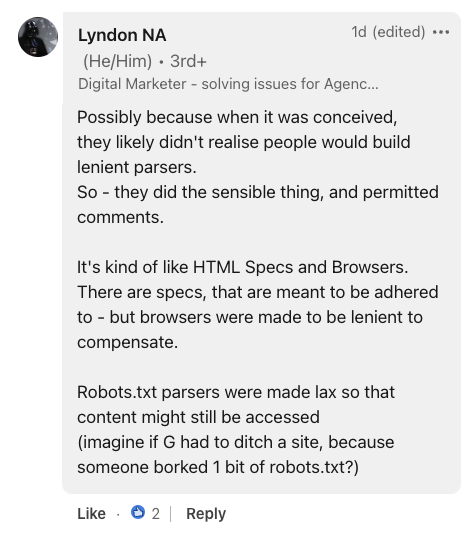
Capture d'écran de LinkedIn, juillet 2024. En fournissant un contexte historique, Lyndon NA, un spécialiste du marketing numérique, a comparé le fichier robots.txt aux spécifications HTML et aux navigateurs.
Il a suggéré que la tolérance aux erreurs du fichier était probablement un choix de conception intentionnel, déclarant :
"Les analyseurs Robots.txt ont été rendus laxistes afin que le contenu puisse toujours être accessible (imaginez si G devait abandonner un site, parce que quelqu'un a falsifié 1 bit de robots.txt ?)."
 Capture d'écran de LinkedIn, juillet 2024.
Capture d'écran de LinkedIn, juillet 2024. Pourquoi SEJ s'en soucie
Comprendre les nuances du fichier robots.txt peut vous aider à mieux optimiser les sites.
Bien que la nature tolérante aux erreurs du fichier soit généralement bénéfique, elle pourrait potentiellement conduire à des problèmes négligés s'il n'est pas géré avec soin.
Lisez aussi : 8 problèmes courants de Robots.txt et comment les résoudre
Que faire avec ces informations
- Vérifiez votre fichier robots.txt : assurez-vous qu'il ne contient que les directives nécessaires et qu'il est exempt d'erreurs potentielles ou de mauvaises configurations.
- Soyez prudent avec l'orthographe : même si les analyseurs peuvent ignorer les fautes d'orthographe, cela pourrait entraîner des comportements d'exploration involontaires.
- Tirer parti des commentaires de ligne : les commentaires peuvent être utilisés pour documenter votre fichier robots.txt pour référence future.
Image en vedette : Sutadisme/Shutterstock



